Batch Rendering using Indirect Draw Call with Vulkan
1. 도입 이유 및 Indirect Draw Call
그래픽스 API를 사용하다보면은 Vertex Buffer와 Index Buffer를 다루게 된다. vkCreateBuffer를 통해서 실행하게 되는데, CPU에서 해당 명령어를 호출하는 순간 Vulkan 드라이버가 CPU에서 동작하며, GPU가 생성 명령을 처리하게 된다.
다만, Mesh마다 Buffer를 만들게 되면 명령 호출이 잦아져 성능 저하를 만들어 내게 된다. 그렇기 때문에 Batching을 도입하여, 해당 부분의 성능 저하를 없애기로 결정하였다.
Indirect Draw Call은 GPU 드로우 커맨드를 미리 준비된 버퍼를 통해 GPU가 직접 참조하여 드로우 명령을 실행하는 방식입니다. 기존의 드로우 방식은 CPU가 각 드로우 호출을 직접 수행하는 방식으로, 많은 수의 드로우 호출이 필요할 때 큰 성능 저하가 발생할 수 있다.
Vulkan에서 제공하는 vkCmdDrawIndexedIndirect 명령어를 통해 드로우 콜 호출을 간접적으로 실행하면 GPU가 직접 VkBuffer에 저장된 드로우 명령들을 읽고 처리한다. 이 방식을 통해 CPU와 GPU 간의 오버헤드를 줄이고 성능을 향상시킬 수 있다.
2. Implement of Batch Rendering
GPU가 읽고 처리할 드로우 명령을 담은 버퍼는 다음의 구조체 형태로 정의된다.
typedef struct VkDrawIndexedIndirectCommand {
uint32_t indexCount;
uint32_t instanceCount;
uint32_t firstIndex;
int32_t vertexOffset;
uint32_t firstInstance;
} VkDrawIndexedIndirectCommand;
위 구조체는 GPU가 드로우 호출을 수행할 때 필요한 정보를 담고 있으며, 각 필드가 나타내는 의미는 다음과 같다.
- indexCount: 이번 드로우 호출에서 사용할 index 개수
- instanceCount: 이번 드로우 호출에서 사용할 인스턴스 개수
- firstIndex: Index Buffer에서 드로우를 시작할 index 위치
- vertexOffset: Vertex Buffer 내에서의 정점의 시작 위치
- firstInstance: 이번 호출의 첫 번째 인스턴스의 ID 값
2.1. Batch Data Processing and Indirect Draw Call Connection
GPU의 성능 최적화를 위해서는 Mesh 데이터(verices, indices)를 각각 개별적으로 GPU로 보내는 대신 일정 크기 이상의 배치로 묶어 전달하는 것이 좋다. 이를 통해 GPU가 하나의 큰 데이터를 여러 번에 나눠 처리하여 효율성을 높이는 것이다.
1. procedure BUILD_BATCH(meshList, Capacity)
2. batch ← new MiniBatch()
3. for each mesh in meshList do
4. vBytes ← mesh.vertexCount × sizeof(Vertex)
5. iBytes ← mesh.indexCount × sizeof(uint32)
6. if batch.size + vBytes + iBytes > Capacity then
# 3개의 버퍼 생성 및 새로운 배치 생성
7. createBuffers(batch)
8. batch ← new MiniBatch()
9. end if
# Draw Commands 기록
10. appendDrawCmd(batch, mesh)
# 정점·인덱스 정보 누적
11. appendData(batch, mesh.vertices, mesh.indices)
12. batch.size ← batch.size + vBytes + iBytes
13. end for
# 배치의 잔여 데이터에 대한 버퍼 생성
14. if batch.size > 0 then
15. createBuffers(batch)
16. end if
17. end procedure
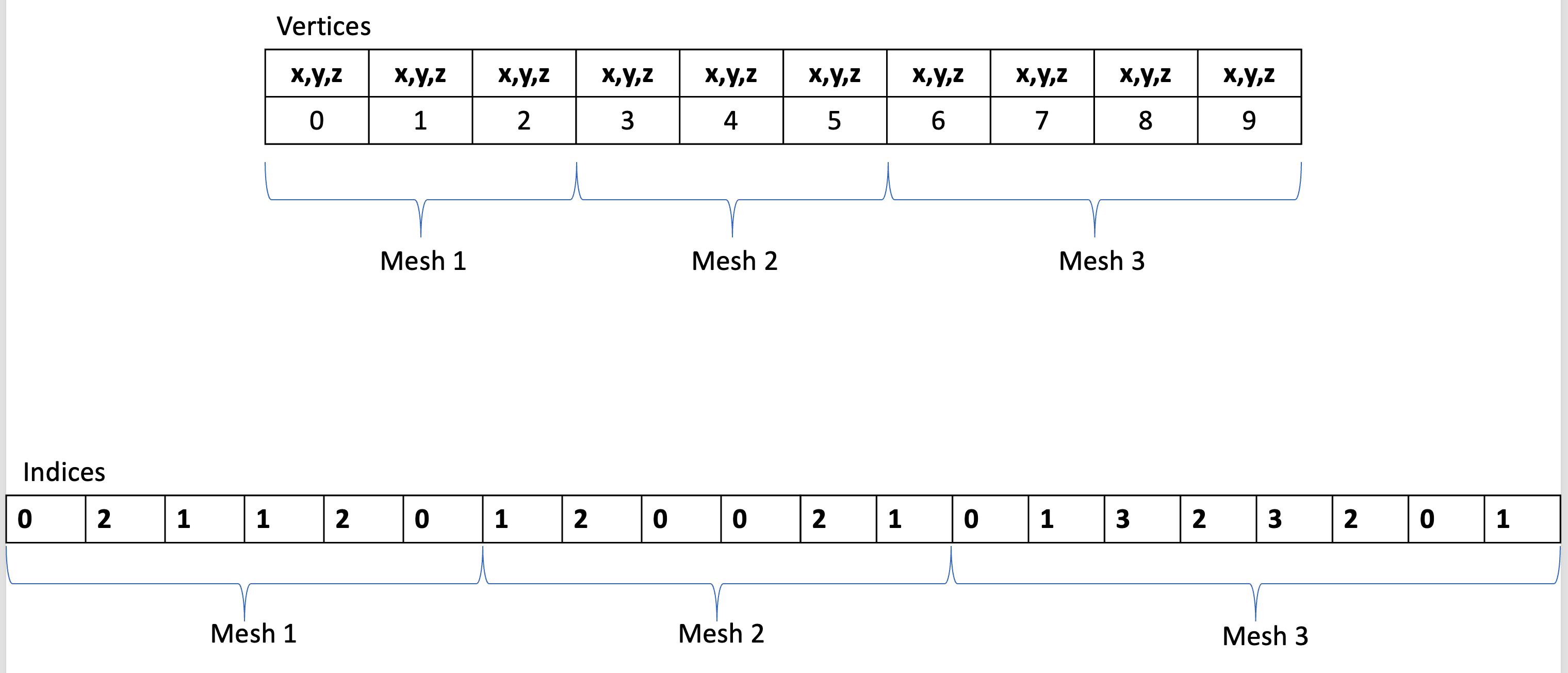
먼저, 여러 메쉬의 Vertex 및 Index 데이터를 하나의 큰 Vertex Buffer 및 Index Buffer에 연속적으로 누적한다. 그리고 각각의 메쉬 데이터를 VkDrawIndexedIndirectCommand를 통해 참조하도록 하여 GPU가 이를 개별적으로 인지하고 처리할 수 있게 한다. 누적하다가가, 지정된 크기(MAX_BATCH_SIZE)에 도달하면 누적된 데이터를 GPU에 전송하여 VkBuffer를 생성한다.
따라서, Batch Rendering의 구조는 매우 단순하다. offset은 IndirectCommand에다가 특정 mesh가 가지는 vertex 정보의 좌표를 가리키는 역할을 수행한다. batchSize는 Batching에서 한 batch마다 최대 특정 사이즈까지만 저장하기 위해 추가한 변수이다. 해당 변수가 mesh의 정보가 누적될 때마다 그에 대한 메모리 용량을 기록해서 현재 mini batch가 다 차면 다음 batch를 생성할 수 있도록 도와주는 것이다.
for(auto& object : objectList) {
SetVertexBuffer(object.vertexBuffer);
SetIndexBuffer(object.indeixBuffer);
Draw();
}
for(auto& batch : batches) {
SetVertexBuffer(batch.vertexBuffer);
SetIndexBuffer(batch.indexBuffer);
IndirectDraw(batch.indirectBuffer);
}
이러한 식으로 반복문이 변하게 된다. 이렇게 되면 1000개의 물체에 대해서 1000번 Draw해야 했던 것을 Batch 시스템과 Indirect를 도입함으로써, 하나의 Batch를 통해서 한 번 Draw 함수를 사용하는 것만으로 렌더링이 가능해진다.
2.2.1 Approach Batch Data in Shader
uint originalIndex = visibleInstances[gl_InstanceIndex];
mat4 model = nonuniformEXT(ssbo_Model.transform[u_ShaderSetting.batchIdx + originalIndex].currentModel);
gl_Position = pushConstants.viewProjection * model * vec4(inPosition, 1.0);
위의 코드처럼 Culling 같은 과정을 거치고서 렌더링 해야하는 instance의 model 행렬의 위치를 알아야 하기 때문에 SSBO를 추가해준다. 향후 shader에서 해당 배열을 사용해서 살아남은 index를 가져온 후, 그 index를 이용해서 model 행렬 배열에 접근하는 것이다.
만일 Texture가 있다면, Texture도 TextureArray[] 형식으로 저장해서 위와 같이 접근해서 사용하면 된다.
3. Experiments
Indirect Draw Call과 배치 단위의 데이터 처리 방식을 결합하면, CPU와 GPU 간의 호출 비용을 최소화하면서도 많은 오브젝트를 렌더링할 수 있게 됩니다. 이를 통해 렌더링 성능 향상은 물론, 전체적인 GPU 활용도를 높여 애플리케이션 성능을 극대화할 수 있다.

그림 2는 mesh의 삼각형 수에 따른 FPS(Frame per second) 성능을 기본 방식(Basic) 과 배치 렌더링 방식(Batch) 으로 나누어 측정한 결과이다. 삼각형 26만개 환경에서 Batch 렌더링 파이프라인이 163.4 프레임을 기록하였고 기본 렌더링 파이프라인이 133.2프레임을 달성하였다. 또한 삼각형 개수를 늘려서 추가 실험을 진행했을 경우에, Batch와 Basic 렌더링 파이프라인의 차이가 커진다는 것을 확인할 수 있었다. 이를 통해서 Batch 렌더링이 드로우콜의 최소화를 통해서 삼각형의 개수가 많아짐에도 불구하고 훨씬 더 안정적이라는 것을 보여준다는 것을 확인했다.
« Halo Effect
Meshlet Rendering using Vulkan »